July 14, 2023
Internet Scraping Vs Web Crawling: Whats The Difference?
Best Guide To Web Scraping With Python Part 1: Requests As Well As Beautifulsoup Although the applications of web spiders are nearly countless, large scalable crawlers often tend to fall under one of several patterns. By finding out these patterns and recognizing the scenarios they apply to, you can greatly boost the maintainability and robustness of your internet crawlers. Currently we can repeat over all Links of tag overview pages, to accumulate more/all web links to articles tagged with Angela Merkel. We repeat with a for-loop over all Links and add arise from each single URL to a vector of all links. Currently, web links has a checklist of 20 hyperlinks to solitary write-ups labelled with Angela Merkel. HTML/ XML things are an organized representation of HTML/ XML source code, which allows to draw out solitary aspects (headlines e.g.Using machine learning to predict student retention from socio ... - Nature.com
Using machine learning to predict student retention from socio ....
Posted: Fri, 07 Apr 2023 07:00:00 GMT [source]
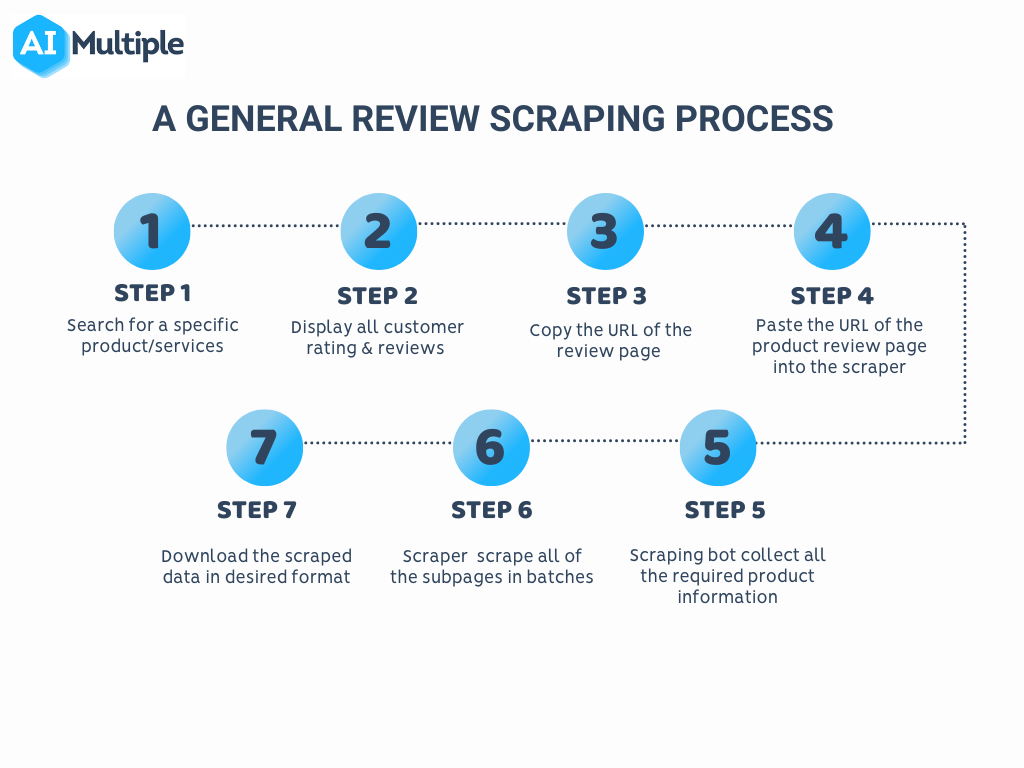
Scuffing Vs Creeping
We are still able to gain access to each thesaurus, d, just as we would typically. In normal editors you'll just import tqdm from tqdm as well as usage tqdm rather. Now, the most convenient means to get all pages is just to by hand make a list of these three pages and also loop over them. If we were dealing with a job with hundreds of web pages we may develop a more computerized method of constructing/finding the following URLs, however, for now this works. The first step of any type of large web scuffing job should be to answer these inquiries. You can make use of these two courses to scratch, as an example, a shop website that may contain post or press releases along with items. Note that the Websiteclass does not store info gathered from the individual web pages themselves, but stores directions abouthowto collect that information. It does not keep the title "My Page Title." It merely keeps the string tag h1 that indicates where the titles can be found.Internet Scuffing With Python, Second Version By Ryan Mitchell
Information crawling is done on a large range that requires added preventative measures so as not to annoy the source or breach any legislations. In conclusion, we can assert that the item of data creeping is to take care of huge data sets where your crawlers are created that crawl to the deepest web pages. On the other hand, data scraping refers to the collection of any type of resource's data. Most of the time, we refer to the removal of data from the web as scuffing, no matter the methods involved, and this is a big mistaken belief. Over 5 billion individuals used the web as of 2022, and each user produces data.- To remove not only the initial, yet all paragraphs we utilize the html_nodes function and glue the resulting single text vectors of each paragraph along with the paste0 feature.
- Once things are set up and also the code is executed, you can open your recommended command-line user interface in your task and runnode.
- After revealing you the pieces, we'll place everything together into a Python manuscript that can be ranged from command line or your IDE of option.
- We repeat with a for-loop over all Links and also add results from each solitary URL to a vector of all links.
Scuffing A Website With Nodejs
On top of all that, you can include spider as well as downloader middlewares in between components as it can be seen in the layout below. The code is extremely simple yet there are numerous efficiency and also usability issues to resolve before successfully creeping a complete site. Usual Crawl keeps an open database of internet creep information. For example, the archive from May 2022 consists of 3.45 billion website. Search engines (e.g. Googlebot, Bingbot, Yandex Bot ...) accumulate all the HTML Legal issues and ethics of web scraping for a considerable component of the Internet. One more point to note is that this spider will certainly get the pages from the web page, but will not proceed crawling after all those pages have been logged.What is the difference between data scuffing as well as data creeping?
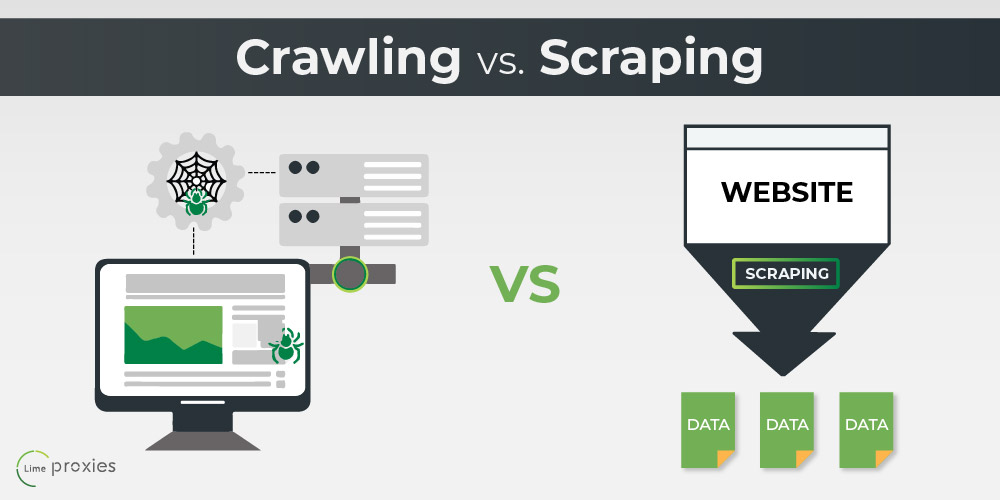
Information creeping is a broader procedure of methodically checking out and indexing data resources, while data scraping is a much more details process of removing targeted information from those sources. Both techniques can be utilized together to essence information from websites, data sources, or other resources.
Social Links